




1. Introduction
Inferential statistics is a branch of statistics that attempts to make valid predictions based on only a sample of all possible observations[1]. For example, imagine a bag of 10,000 marbles. Some are black and some white, but of which the exact proportion of these colours is unknown. It is unnecessary to count all the marbles in order to make some statement about this proportion. A randomly acquired sample of 1,000 marbles may be sufficient to make an inference about the proportion of black and white marbles in the entire population. If 40% of our sample are white, then we may be able to infer that about 40% of the population are also white.
To the layperson, this process seems rather straight forward. In fact, it might seem that there is no need to even acquire a sample of 1,000 marbles. A sample of 100 or even 10 marbles might do.
This is assumption is not necessarily correct. As the sample size becomes smaller, the potential for error grows. For this reason, inferential statistics has developed numerous techniques for stating the level of confidence that can be placed on these inferences.
If we took ten samples of 100 marbles each, we might find the following results:
| Sample Number | Number of White Marbles |
Number of Black Marbles |
|---|---|---|
| 1 | 40 | 60 |
| 2 | 35 | 65 |
| 3 | 47 | 53 |
| 4 | 50 | 50 |
| 5 | 31 | 69 |
| 6 | 25 | 75 |
| 7 | 36 | 64 |
| 8 | 20 | 80 |
| 9 | 45 | 55 |
| 10 | 55 | 45 |
We are then in a position to calculate the "Standard Deviation" of these samples:
where x2 is the sum of the squares so that the equation is expanded to:
and n is the number of samples. In our example, the mean number of White marbles is ![]() .
.
We might be tempted to say that about 40% of the marbles are white, but we are unable to argue that point with any degree of certainty. Using equation 2 above, we determine that the Standard Deviation is 11.15. We must then determine the "Sample Error of the Mean" (where s=[sigma]):
The confidence we can put on our hypothesis that u=40 of the marbles are white is found using a standard statistical test called the "z-test":
Using a z-test table [3] and our resulting z-value of -.4532, we find that 32% of the area of the normal curve would fall below this "z" value. In other words, in 32% of samples given ![]() ,
, 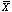 would be less than 38.4. Since the distribution is two-sided or "two-tailed" (i.e. the sample average could also be greater than the population average), we would also expect
would be less than 38.4. Since the distribution is two-sided or "two-tailed" (i.e. the sample average could also be greater than the population average), we would also expect ![]() to greater than ((u-
to greater than ((u-![]() )+u=) 41.6 in another 32% of cases.
)+u=) 41.6 in another 32% of cases.
In summary, if we expect 40% of all marbles in the bag to be white, then a series of ten samples with only 38.4% of marbles being white would be expected in (100-64%=) 36% of the time. Clearly, the confidence we can place in our conclusion is not as good as it was on first glance. This lack of confidence is due to the high variability among the samples. If we took more samples or larger samples, our confidence in our conclusion might increase.